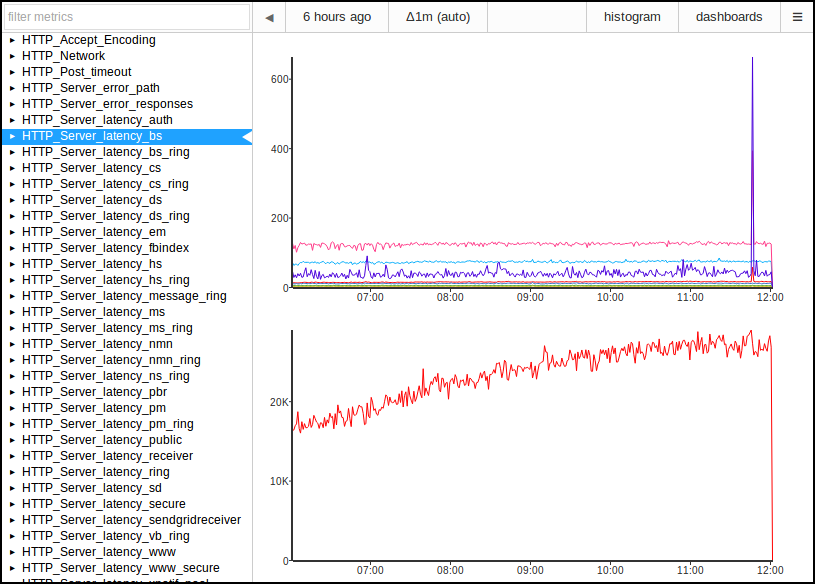
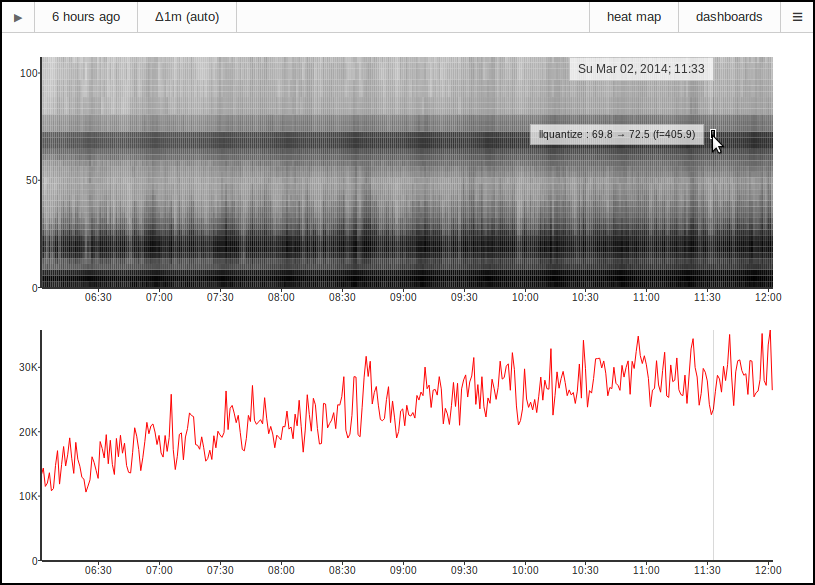
Voxer is always trying to lower the latency between our users. Our data shows that
as we reduce latency, people send more messages. We've done a lot of optimizations on
the backend to improve the performance of our technology stack: node.js, riak, redis,
and SmartOS. The next set of improvements we have been working on are at the network
protocol level by tuning stud and moving to the SPDY protocol, which forms the
basis of HTTP 2.0.
Our mobile clients have always used HTTPS to talk to the backend, but this has caused a
number of performance problems. The latency of mobile networks is unpredictable, and it
fluctuates wildly. Even using persistent connections and HTTP pipelining,
we used a pool of HTTPS connections to reduce client latency and to address issues like head-of-line blocking.
Negotiating and maintaining a pool of TLS connections is complex and slow,
and we haven't found a library that does this well on iOS.
The benefits of SPDY from a networking perspective are well documented. We have
found that using SPDY for our application has made the application easier to understand, debug,
and maintain. SPDY uses a single TCP socket for all requests, so error handling logic,
queuing, retry, and background modes have all gotten simpler.
Twitter has released their CocoaSPDY library which solves a
similar problem to iSPDY. Had this library been available when we started using SPDY, we may have chosen
to use it instead and extend it to our needs. At this point, iSPDY has been tailored for our
specific use case at Voxer, and we will continue to maintain it going forward.
The most important feature in iSPDY that we are relying on heavily is Server Push streams.
Older Voxer clients used WebSockets or traditional HTTP long-polling to get live updates, but
both of these have various tradeoffs at the client, server, and networking levels. In our
application, SPDY with server push is the ideal solution for live updates. A single long-lived
TCP connection can be used to send multiple live media streams to a waiting client without
waiting for a round trip or causing head-of-line blocking from a slow sender.
Here are our design goals for iSPDY:
- low latency tuning options
- low memory footprint
- server push stream support
- priority scheduling for outgoing data
- trailing headers
- ping support
- transparent decompression of response using Content-Encoding header
- background socket reclaim detection and support on iOS
- VoIP mode support on iOS
- optionally use IP instead of DNS name to connect to server and save DNS resolution time
Adding support for SPDY on our backend was relatively straightforward because we are
using node.js and node-spdy. Fedor Indutny is the primary author of both iSPDY
and node-spdy, so these two libraries work well together. We use stud for TLS
termination, so node.js sees an unencrypted SPDY stream, which is supported by node-spdy.
Older clients and those on other platforms will continue to send HTTPS, but node-spdy has
HTTP fallback support. The server code handling these endpoints is almost entirely unchanged,
which has made testing and integrating SPDY much easier.
You can download and play with iSPDY on github.
read more...
 Voxer Engineering
Voxer Engineering